Examine outputs
The outputs of a metabarcoding workflow and their basic reading are described in the outputs section of “What is a metabarcoding workflow?”.
In this section, we will examine the outputs of a metabarcoding workflow in relation to user collected environmental metadata to inspect basic patterns of species (metabarcoding features) richness and composition across different environments.
Here, we illustrate the calculation of species (OTU) richness and composition using the metabarcoding outputs from the BGE case study of high mountain systems dataset, restricted here to samples from Norway, as an example. The data are Malaise trap samples collected weekly in 2023 over 20 weeks across 5 altitudes.
We examine:
Was sequencing depth sufficient?
OTU richness patterns across sampled altitudinal gradient and sampling season.
Input data
OTU table
Sample metadata
example of an OTU table
sample1 |
sample2 |
sample3 |
sample4 |
… |
|
OTU_01 |
579 |
0 |
0 |
0 |
… |
OTU_02 |
405 |
345 |
449 |
430 |
… |
OTU_03 |
0 |
0 |
231 |
69 |
… |
OTU_04 |
0 |
62 |
345 |
0 |
… |
1#!/usr/bin/Rscript
2
3# Working directory and results directory paths
4wd = "path/to/your/working/directory"
5results = file.path(wd, "results")
6
7# OTU table
8OTU.table = file.path(wd, "OTU_table.csv")
9
10# Sample metadata
11sampleMetadata = file.path(wd, "metadata.csv")
Sequencing depth
Sequencing depth is the total number of sequences in a sample. Although the amplicon library is pooled in equimolar concentrations prior to sequencing, there can be still considerable variation in sequencing depth between samples. If so, then for the statistical analyses, it is important to account for this variation.
One way to account for this variation is to normalise sequencing depth to a common value, which can be achieved through rarefaction analysis.
Another way to account for this variation is to use sequencing depth per sample as a covariate in the statistical analyses. By including sequence counts per sample as a predictor, differences in species richness or composition are evaluated after statistically adjusting for variation in sequencing depth.
Note
With the bioinformatic processing (and post-processing steps), we are trying to remove noise from the sequencing data, but this inherently may filter out some true (low abundance) taxa. Therefore, rarfaction analyses after the bioinformatic processing tries to answer the question: “was sequencing depth sufficient to capture the taxa that pass our quality filters?”, not “was sequencing depth sufficient to capture all true taxa in the sample”.
Here, we are examining if the sequencing depth per samples has been sufficient, i.e., do the OTU accumulation curves flatten out (reach the asymptote)?
1#!/usr/bin/Rscript
2
3# Compute rarefaction curves for each sample
4set.seed(1)
5library(vegan)
6rarecurve_data = rarecurve(
7 t(OTU_table), # transpose so samples are rows
8 step = 5000, # step size (seqs) in rarefaction curves
9 col = "steelblue",
10 label = FALSE
11)
12
13# Convert the list returned by rarecurve() into a tidy data frame
14library(purrr)
15library(dplyr)
16library(tidyr)
17
18rarecurve_data_to_ggplot =
19 map_dfr(rarecurve_data, bind_rows) %>%
20 bind_cols(Group = colnames(OTU_table), .) %>%
21 tidyr::pivot_longer(-Group) %>%
22 tidyr::drop_na() %>%
23 mutate(
24 n_seqs = as.numeric(stringr::str_replace(name, "N", ""))
25 ) %>%
26 select(-name)
27
28# Plot rarefaction curves (richness vs sequences) for all samples
29p_rarefaction =
30 ggplot(data = rarecurve_data_to_ggplot,
31 aes(x = n_seqs, y = value, group = Group)) +
32 geom_line(alpha = 0.6, color = "steelblue") +
33 theme_minimal() +
34 labs(x = "Number of sequences",
35 y = "Number of OTUs",
36 title = "Rarefaction curves per sample") +
37 theme(
38 legend.text = element_text(size = 12),
39 legend.title = element_text(size = 14),
40 axis.text = element_text(size = 11),
41 axis.title = element_text(size = 12),
42 plot.title = element_text(size = 16)
43 )
44
45# Save plot
46ggsave(
47 filename = file.path(results, "rarefaction_curves.png"),
48 plot = p_rarefaction,
49 width = 8, height = 6, dpi = 300)
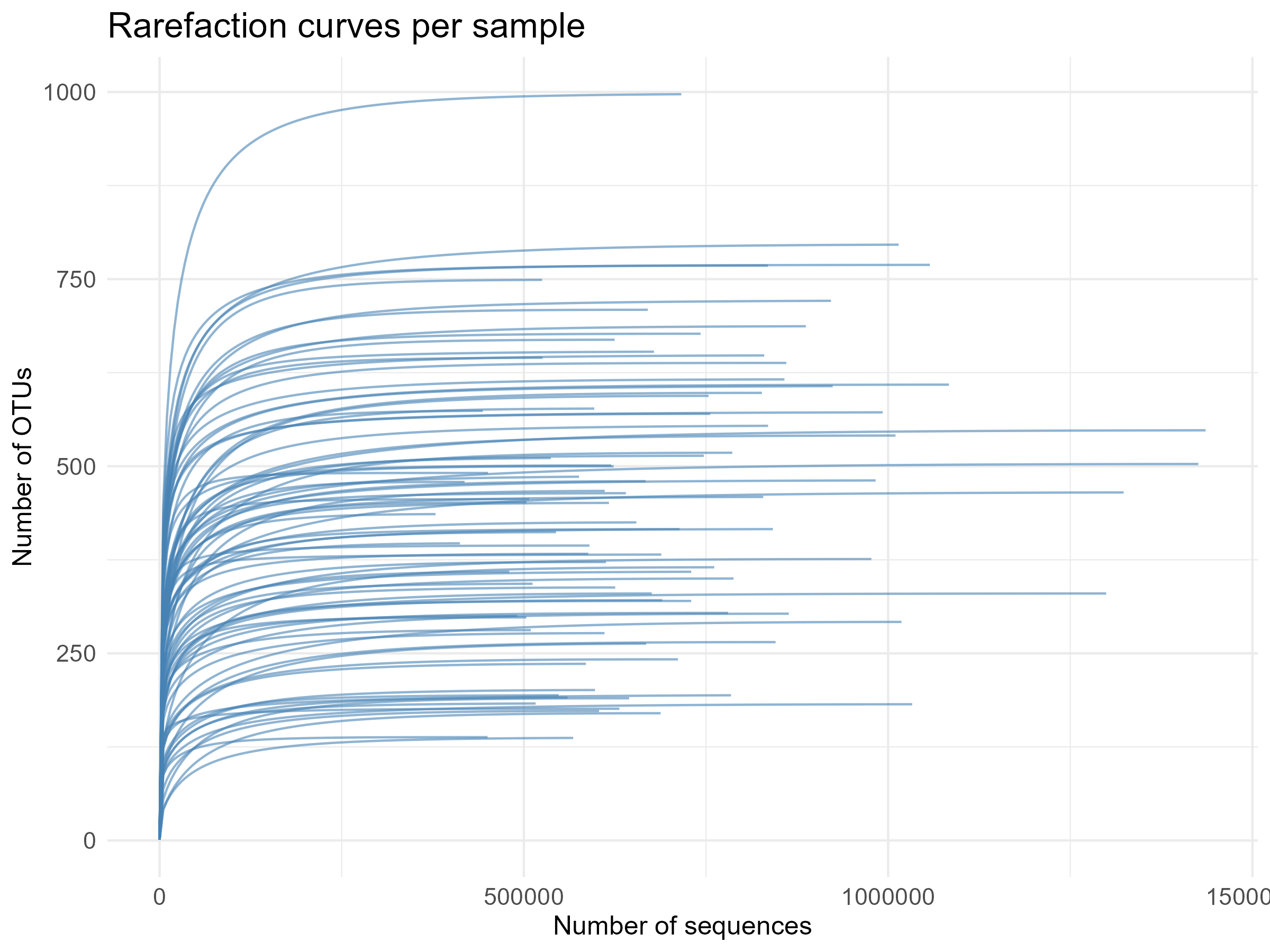
The resulting plot shows the OTU accumulation curves for each sample. Most curves rise steeply at low read numbers and then level off, indicating that additional sequencing yields few (or no) new OTUs and that sequencing depth is generally sufficient for capturing the diversity in these samples.
Now, let’s confirm this by calculating the slope of the rarefaction curve for each sample. A small slope means that adding many more sequences yields very few new OTUs (curve is flat), so sequencing depth for that sample is likely sufficient; a larger slope indicates the curve is still rising and the sample may be under-sequenced.
1#!/usr/bin/Rscript
2
3### Calculate the slope of the rarefaction curve
4 # The slope between the last two points of each sample's curve indicates
5 # whether the curve has flattened (asymptote ≈ slope close to 0).
6asymptote_info = rarecurve_data_to_ggplot %>%
7 group_by(Group) %>%
8 arrange(n_seqs) %>%
9 summarise(
10 last_depth = last(n_seqs),
11 last_richness = last(value),
12 prev_depth = nth(n_seqs, -2),
13 prev_richness = nth(value, -2),
14 slope = (last_richness - prev_richness) / (last_depth - prev_depth)
15 )
16
17## Define a slope threshold for asymptote
18threshold = 0.001 # ≈ 5 new OTUs per 5,000 additional sequences
19# threshold = 0.0002 # more conservative: ≈ 1 new OTU per 5,000 sequences
20
21# Mark samples whose curves have effectively reached asymptote
22asymptote_info = asymptote_info %>%
23 mutate(
24 at_asymptote = abs(slope) < threshold # or use (last_richness - prev_richness) < 5
25 )
26
27# How many samples reached asymptote?
28sum(asymptote_info$at_asymptote)
29 #-> 88 samples reached to asymptote according to our threshold
30
31# Show samples that did NOT reach asymptote
32not_at_asymptote = asymptote_info %>%
33 filter(!at_asymptote) %>%
34 select(Group, last_depth, last_richness, slope)
35
36not_at_asymptote
37 #-> Group last_depth last_richness slope
38 # BGE-HMS1295 8196 249 0.00108
39
40# Summary statistics of sequences per sample
41summary(asymptote_info$last_depth)
42 #-> Min. 1st Qu. Median Mean 3rd Qu. Max.
43 # 8196 575683 675578 716605 835014 1435769
Based on our threshold
(5 new OTUs per 5,000 additional sequences),
sample BGE-HMS1295 fails to reach the asymptote.
Indeed, we see that this sample has relatively low sequencing
depth (8,196 sequences)
compared to the median (675,578 sequences) and mean (716,605 sequences).
Because, the sample BGE-HMS1295 has cleary failed,
we will remove it from the analysis.
1#!/usr/bin/Rscript
2
3# Remove sample BGE-HMS1295 from the analysis
4remove_samples = c("BGE-HMS1295")
5OTU_table = OTU_table[, -which(colnames(OTU_table) %in% remove_samples)]
6
7# Check the dimensions of the OTU table
8dim(OTU_table)
9 # -> 5839 OTUs, 88 samples (after removing sample BGE-HMS1295)
10
11# Remove OTUs with zero sequences
12OTU_table = OTU_table[rowSums(OTU_table) > 0, ]
13dim(OTU_table)
14 # -> 5834 OTUs (after removing OTUs with zero sequences)
15
16## Beause we removed a sample and OTUs with zero sequences,
17 ## we need to update the sample metadata
18sample_metadata = sample_metadata[colnames(OTU_table), ]
19
20#-------------------------------#
21## Sequence summary statistics ##
22# Assess variability in sequencing depth per sample
23sequences_per_sample <- colSums(OTU_table)
24mean_depth <- mean(sequences_per_sample)
25sd <- sd(sequences_per_sample)
26cv <- sd_depth / mean_depth # coefficient of variation
27range <- range(sequences_per_sample)
28
29cat("\nMean depth:", round(mean_depth), "\n")
30 #-> Mean depth: 724655
31cat("Standard deviation:", round(sd), "\n")
32 #-> Standard deviation: 218800
33cat("Coefficient of variation:", round(cv, 3), "\n")
34 #-> Coefficient of variation: 0.302
35cat("Range (min, max):", paste(range, collapse = " - "), "\n")
36 #-> Range (min, max): 378741 - 1435769
We have removed the sample with low sequencing depth. The remaining samples have a mean sequencing depth of 724,655 sequences. The number of sequences per sample range from 378,741 to 1,435,769 sequences, and the coefficient of variation is 0.302. Latter means that the standard deviation of read depth is about 30% of the mean sequencing depth. Sequencing effort differs moderately between samples, thus it would be reasonable to include sequencing depth as a covariate in the statistical analyses.
Below, we plot the sequencing depth per sample by sampling week. We see that the sequencing depth decreases with the sampling week (towards autumn).
1#!/usr/bin/Rscript
2
3# Build sample_richness dataframe for downstream analyses
4library(dplyr)
5sample_richness <- tibble(
6 sample = colnames(OTU_table),
7 richness = colSums(OTU_table > 0)
8) %>%
9 left_join(
10 sample_metadata %>%
11 as.data.frame() %>%
12 tibble::rownames_to_column("sample"),
13 by = "sample"
14 ) %>%
15 mutate(sequencing_depth = as.numeric(colSums(OTU_table)[sample]))
16
17## Plot sequencing depth per sample by sampling week
18p = ggplot(sample_richness,
19 aes(x = week,
20 y = sequencing_depth)) +
21 geom_point(aes(color = sequencing_depth),
22 size = 2, alpha = 0.8) +
23 scale_color_viridis_c(option = "plasma",
24 name = "Sequencing depth") +
25 geom_smooth(method = "lm",
26 formula = y ~ poly(x, 2),
27 aes(group = 1),
28 color = "darkgreen") +
29 labs(
30 title = "Sequencing depth per sample by sampling week",
31 x = "Week",
32 y = "Number of sequences"
33 ) +
34 theme_bw()
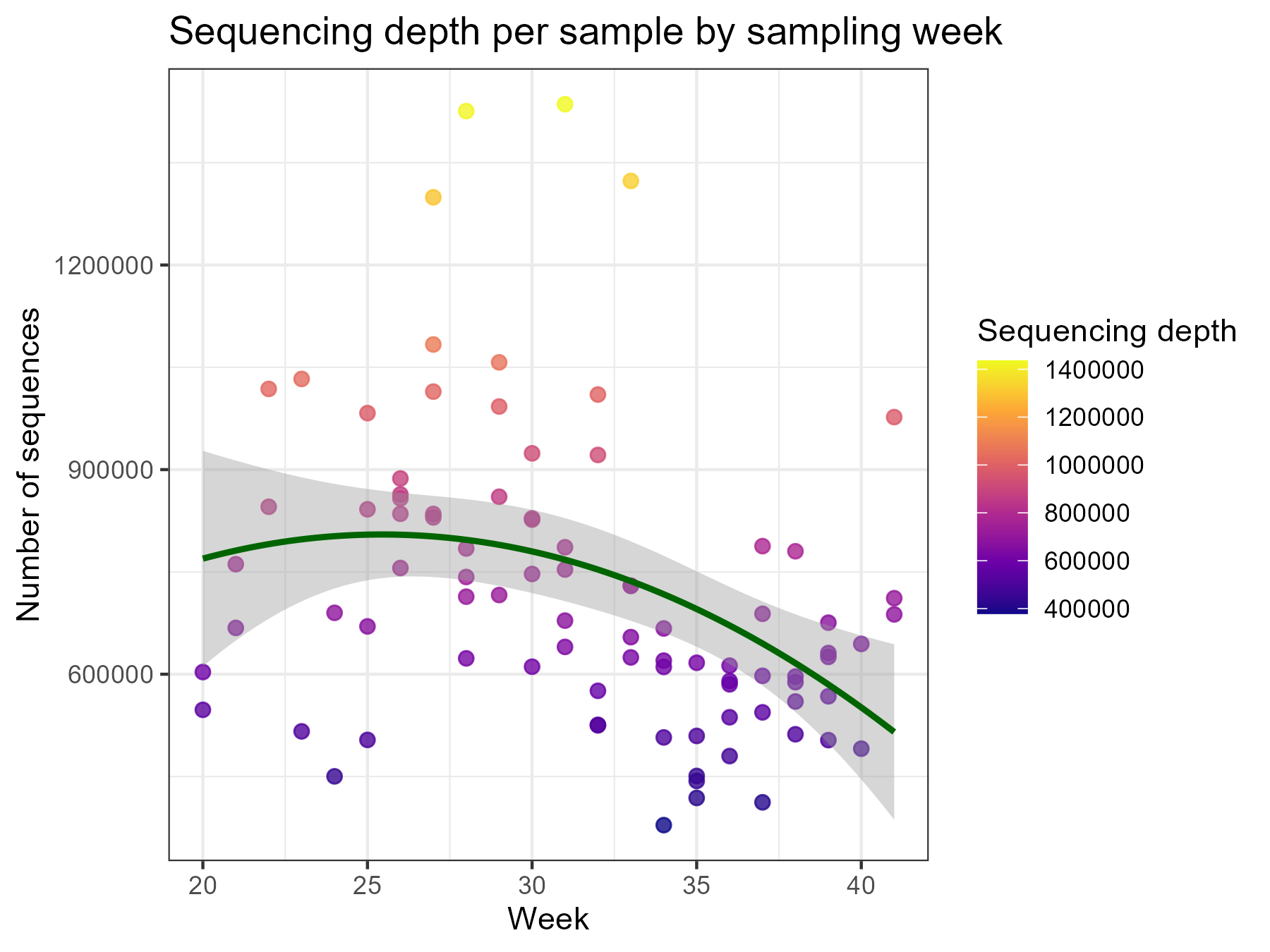
If we would like to test if the OTU richness differs between sampling seasons (spring, summer, autumn), then we would need to include sequencing depth as a covariate in the statistical analyses to separate the effect of sequencing depth from the effect of sampling season — even though all samples showed sufficient sequencing depth (rarefaction curves reached asymptote). If we would not include sequencing depth as a covariate, then the effect of sampling season would be confounded by the effect of sequencing depth (even when all samples reached asymptote, samples with higher depth can still have slightly higher observed OTU richness, so when depth differs between seasons the raw season effect on richness mixes biology with that technical effect).
Richness
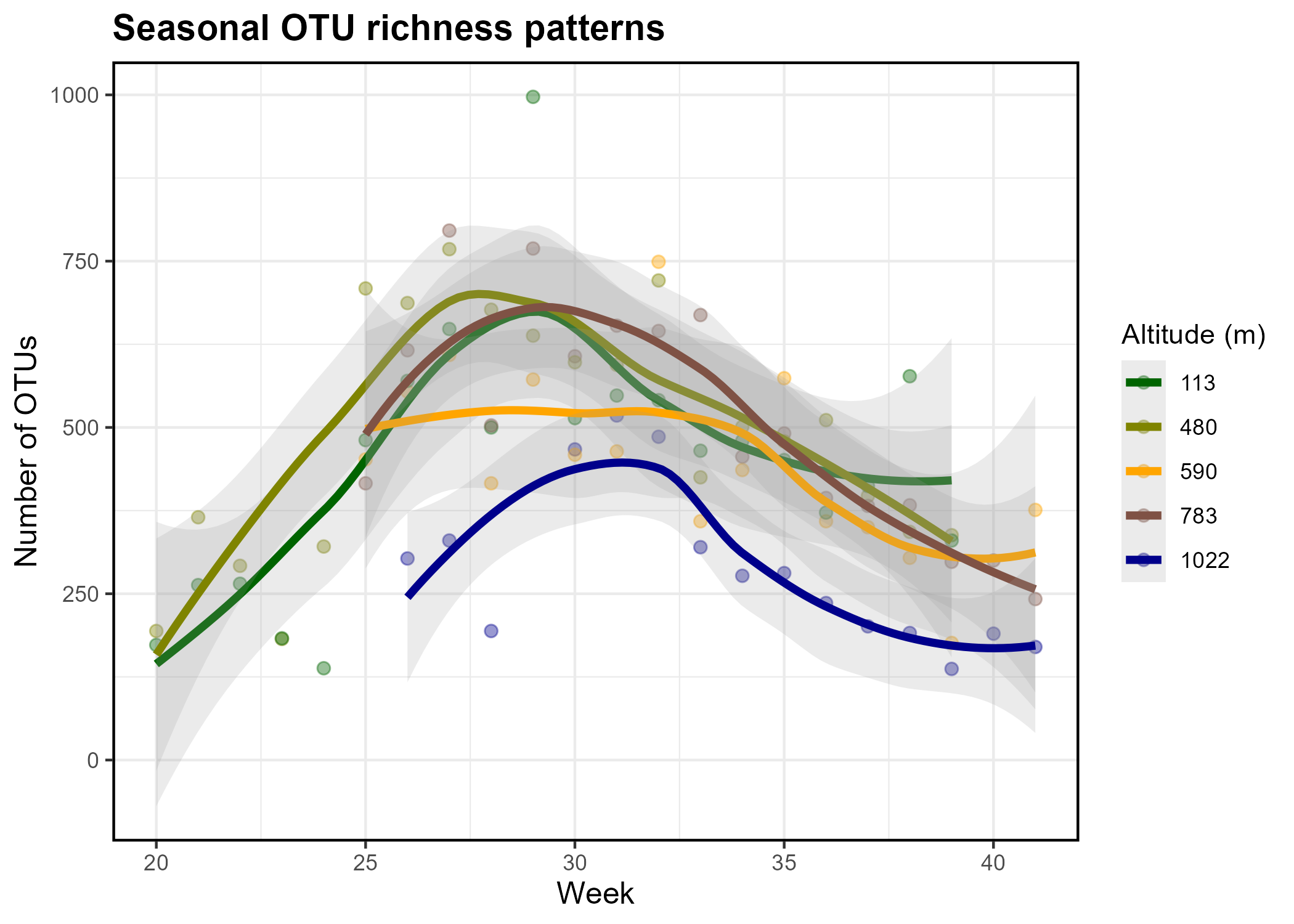
Let’s further examine the number of OTUs across the altitudinal gradient.
1#!/usr/bin/Rscript
2
3library(tidyverse)
4
5sample_names = colnames(OTU_table)
6
7# OTU richness for a given altitude
8richness_for_alt = function(alt) {
9 these_samples = rownames(sample_metadata)[sample_metadata$altitude == alt]
10 these_samples = intersect(these_samples, sample_names)
11
12 if (length(these_samples) == 0) return(0L)
13
14 mat = as.matrix(OTU_table[, these_samples, drop = FALSE])
15 sum(rowSums(mat > 0) > 0)
16}
17
18# unique altitudes in sample metadata, sorted for plotting
19alts = sort(unique(sample_metadata$altitude))
20
21# create a dataframe with altitude and OTU richness
22richness_by_altitude = tibble(
23 altitude = alts,
24 n_species = vapply(alts, richness_for_alt, integer(1))
25)
26
27# plot total richness vs altitude
28p_tot = ggplot(richness_by_altitude,
29 aes(x = altitude, y = n_species, group = 1)) +
30 geom_line(aes(color = "Linear trend (lm)"), linewidth = 1) +
31 geom_smooth(aes(color = "Linear trend (lm)"),
32 method = "lm", se = TRUE,
33 linewidth = 0.9, show.legend = FALSE) +
34 geom_point(aes(color = "Altitude-specific richness"), size = 4) +
35 geom_text(aes(label = n_species),
36 vjust = -0.8, size = 3, color = "black") +
37 scale_color_manual(
38 name = "",
39 values = c(
40 "Altitude-specific richness" = "black",
41 "Linear trend (lm)" = "lightblue"
42 )
43 ) +
44 labs(
45 title = "Total OTU richness across altitude",
46 x = "Altitude (m)",
47 y = "OTU richness"
48 ) +
49 theme_bw(base_size = 12) +
50 theme(
51 plot.title = element_text(face = "bold"),
52 panel.grid.minor = element_blank(),
53 legend.position = "bottom"
54 )
55
56# Save plot
57ggsave(
58 filename = file.path(results, "richness_by_altitude.png"),
59 plot = p_tot,
60 width = 5, height = 4.5, dpi = 300)
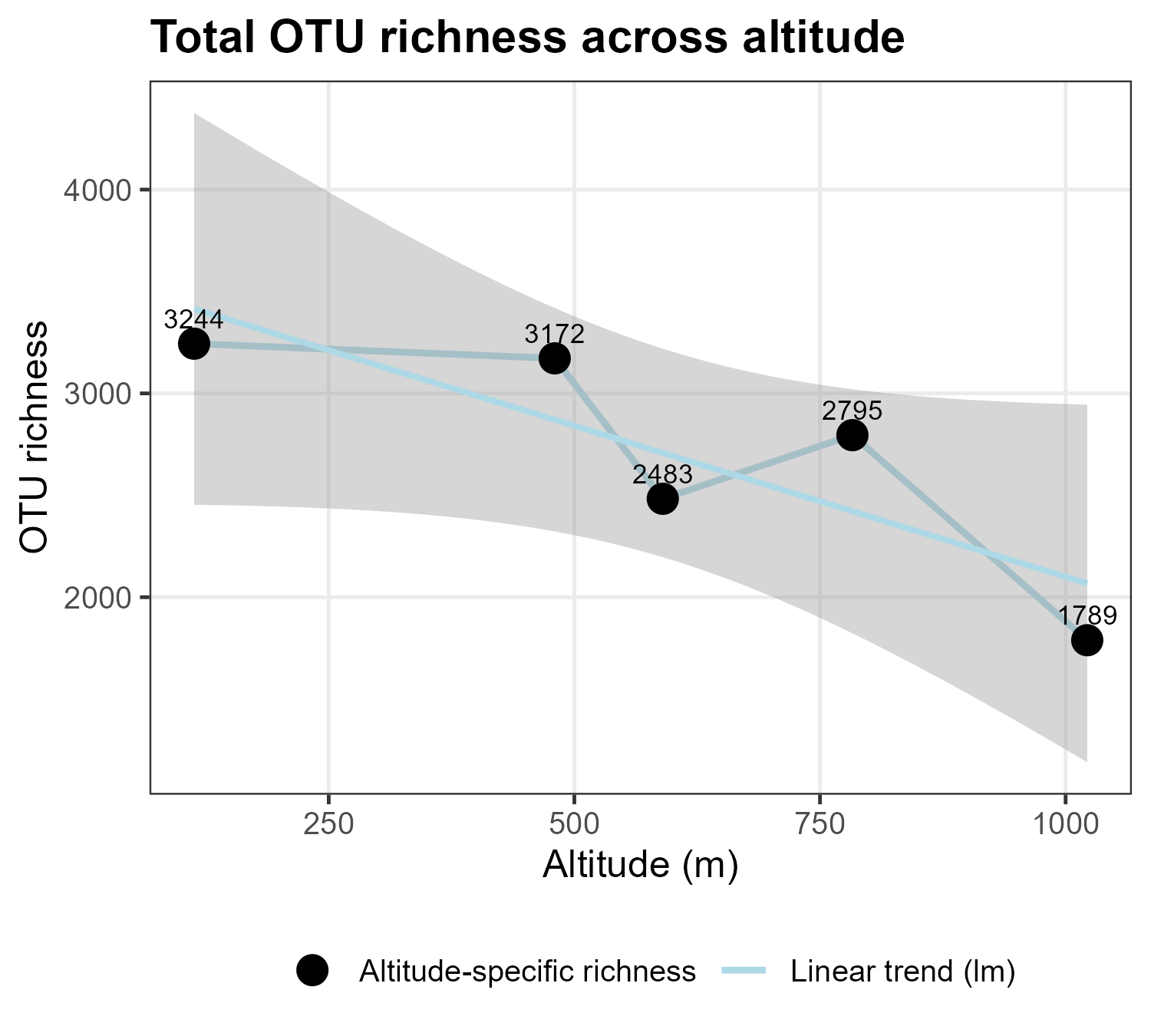
The resulting pattern suggests that total OTU richness tends to decline towards higher elevations. This is an expected pattern, as environmental stress increases with altitude, especially in the higher latitude regions (such as Norway in that example dataset).
Let’s test this relationship more formally.
1#!/usr/bin/Rscript
2
3# Use Generalized Linear Model (GLM) with negative binomial
4# distribution to model the richness data.
5# Negative binomial distribution is a common choice for count data
6# with overdispersion (variance > mean).
7library(MASS)
8
9# log10 transform the sequencing_depth
10sample_richness$log_sequencing_depth =
11 log10(sample_richness$sequencing_depth)
12
13# Fit linear and quadratic models (with altitude and sequencing depth)
14glm_richness_linear = glm.nb(
15 richness ~ altitude + log_sequencing_depth,
16 data = sample_richness
17)
18glm_richness_quad = glm.nb(
19 richness ~ poly(altitude, 2) + log_sequencing_depth,
20 data = sample_richness
21)
22
23# Compare: is quadratic better than linear?
24anova(glm_richness_linear, glm_richness_quad, test = "Chisq")
25 # -> Pr(Chi = 0.0006887357
26
27
28# Quadratic model summary (coefficients on log(mean richness) scale)
29summary(glm_richness_quad)
30# Estimate Std. Error z value Pr(>|z|)
31# (Intercept) 0.9717 1.9283 0.504 0.614320
32# poly(altitude, 2)1 -0.8119 0.3778 -2.149 0.031645 *
33# poly(altitude, 2)2 -1.3591 0.3765 -3.610 0.000307 ***
34# log_sequencing_depth 0.8727 0.3300 2.645 0.008175 **
35
36## Deviance-based pseudo-R2
37pseudo_R2_richness_quad =
38 1 - (glm_richness_quad$deviance / glm_richness_quad$null.deviance)
39cat("Pseudo-R2 (glm_richness_quad): ", round(pseudo_R2_richness_quad, 4), "\n")
40 #-> Pseudo-R2 (glm_richness_quad): 0.2002
41
42# Plot richness vs altitude with linear and quadratic fits
43library(ggplot2)
44p = ggplot(sample_richness,
45 aes(x = altitude, y = richness)) +
46 geom_point(size = 3, alpha = 0.8) +
47 geom_smooth(method = "lm", aes(linetype = "Linear"),
48 color = "gray", se = F) +
49 geom_smooth(method = "lm", formula = y ~ poly(x, 2),
50 aes(linetype = "Quadratic"),
51 color = "darkgreen", se = TRUE) +
52 scale_linetype_manual(name = "Trend",
53 values = c(Linear = "dashed",
54 Quadratic = "solid")) +
55 labs(
56 title = "OTU richness by altitude",
57 x = "Altitude (m)",
58 y = "OTU richness"
59 ) +
60 theme_bw()
61
62ggsave(
63 filename = file.path(results, "richness_by_altitude2.png"),
64 plot = p,
65 width = 6, height = 4.5, dpi = 300
66)
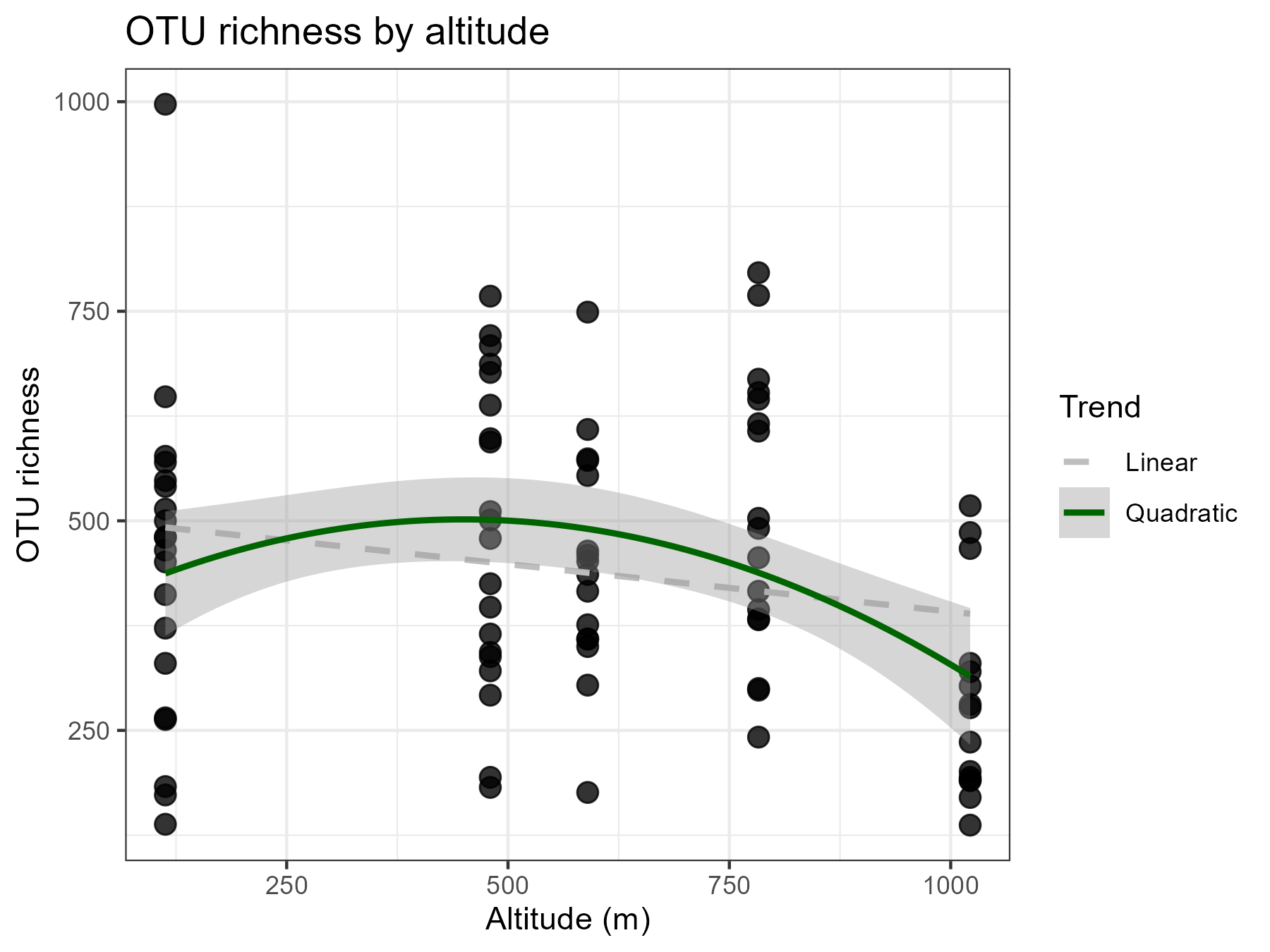
A negative-binomial GLM of OTU richness on altitude and sequencing depth was significantly improved by adding a quadratic altitude term (likelihood-ratio test p ≈ 0.0007). That is, OTU richness changes significantly across the altitudinal gradient, in a curved rather than linear way. The model explains about 20% of the null deviance in richness (pseudo-R2 = 0.20), so other potential drivers (e.g. habitat, season) are not captured in this model.
As we can notice from the plot above (and below), the per altitude richness is highly variable, and that originates from the sampling across 20 weeks at each altitude. Thus, let’s include seasonality into the model.
1#!/usr/bin/Rscript
2
3library(MASS)
4# GLM for OTU richness with altitude, sequencing depth, and seasonality
5glm_season = glm.nb(
6 richness ~ poly(altitude, 2) +
7 log_sequencing_depth +
8 cos(2 * pi * week / 52) + # annual cycle as a cosine function
9 sin(2 * pi * week / 52), # annual cycle as a sin function
10 data = sample_richness
11)
12summary(glm_season)
13#->
14# Estimate Std. Error z value Pr(>|z|)
15# (Intercept) 2.11097 1.45721 1.449 0.147439
16# poly(altitude, 2)1 -1.04241 0.27319 -3.816 0.000136 ***
17# poly(altitude, 2)2 -1.30751 0.26214 -4.988 6.11e-07 ***
18# log_sequencing_depth 0.47899 0.25160 1.904 0.056946 .
19# cos(2 * pi * week/52) -1.18471 0.11981 -9.888 < 2e-16 ***
20# sin(2 * pi * week/52) -0.78676 0.09008 -8.734 < 2e-16 ***
21#
22
23
24## Compare glm_season to model without seasonal terms
25# Deviance-based pseudo-R2:
26pseudoR2_quad = 1 - (glm_richness_quad$deviance / glm_richness_quad$null.deviance)
27pseudoR2_season = 1 - (glm_season$deviance / glm_season$null.deviance)
28
29cat("Pseudo-R2 (quad):", pseudoR2_quad)
30 #-> Pseudo-R2 (quad): 0.2001701
31cat("Pseudo-R2 (season):", pseudoR2_season)
32 #-> Pseudo-R2 (season): 0.6192453
33
34## AIC comparison
35AIC_quad = AIC(glm_richness_quad)
36AIC_season = AIC(glm_season)
37cat("AIC (quad):", AIC_quad)
38 #-> AIC (quad): 1147.558
39cat("AIC (season):", AIC_season)
40 #-> AIC (season): 1085.174
41
42## Compare using anova test (Likelihood Ratio Test)
43anova(glm_richness_quad, glm_season, test = "Chisq")
44 #-> Pr(Chi) = 3.885781e-15
In addition to altitude, the seasonality (cosine and sine of week) is a significant driver of insect OTU richness (p < 0.0001). Comapred with model that did not have seasonality terms included, the model with seasonality had much higher pseudo-R2 (0.619 vs 0.200); indicating a substantial increase in the model’s explanatory power. This increase was not simply due to overfitting, as the likelihood-ratio test shows that the model with seasonality fits significantly better than the model without it (p < 0.0001), had lower AIC (1085 vs 1148).
![]()

![]()
![]()